things i wish i know when scraping
speed go is speed.
moneypremature optimization is the root of all evil in programming
-Donald Knuth
before you read on
have you ever feel, when you have moved on from a project and starting a new one, then you found out something that can actually make the prior project runs faster? well i had. so many damn times. so i hope this can be the cure of your wrath. or even before. lol.
background context
so before i explain the problem, you’ll need to know what is the difference between serial, paralell, and concurrent running.
serial vs parallelism vs concurrency
serial
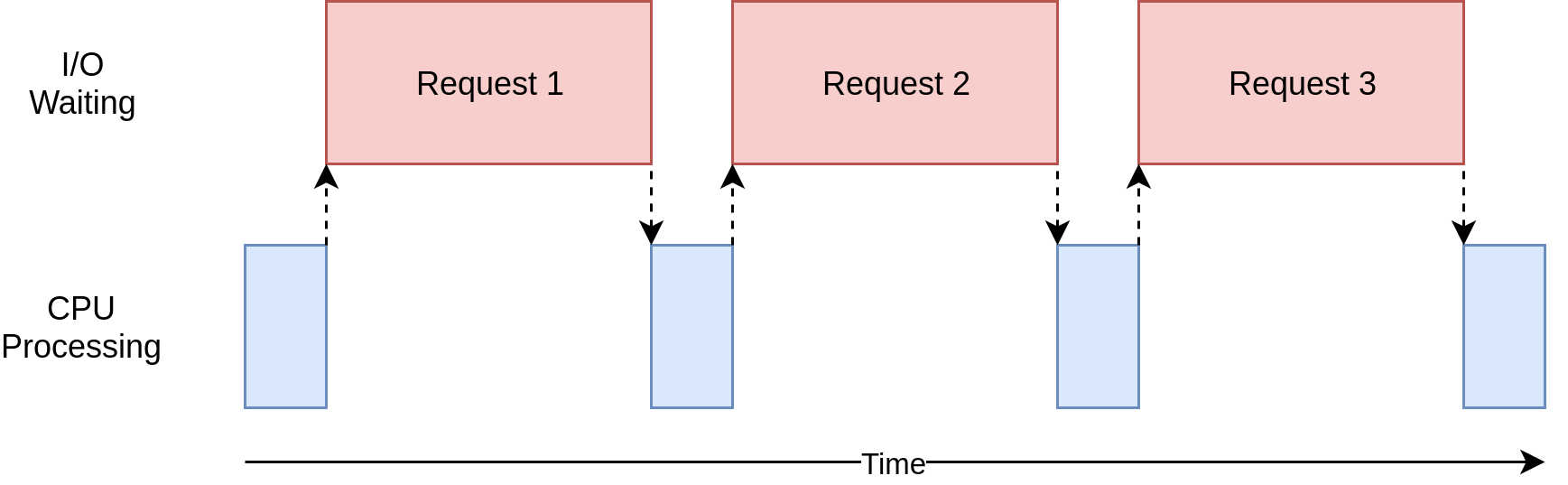
parallelism
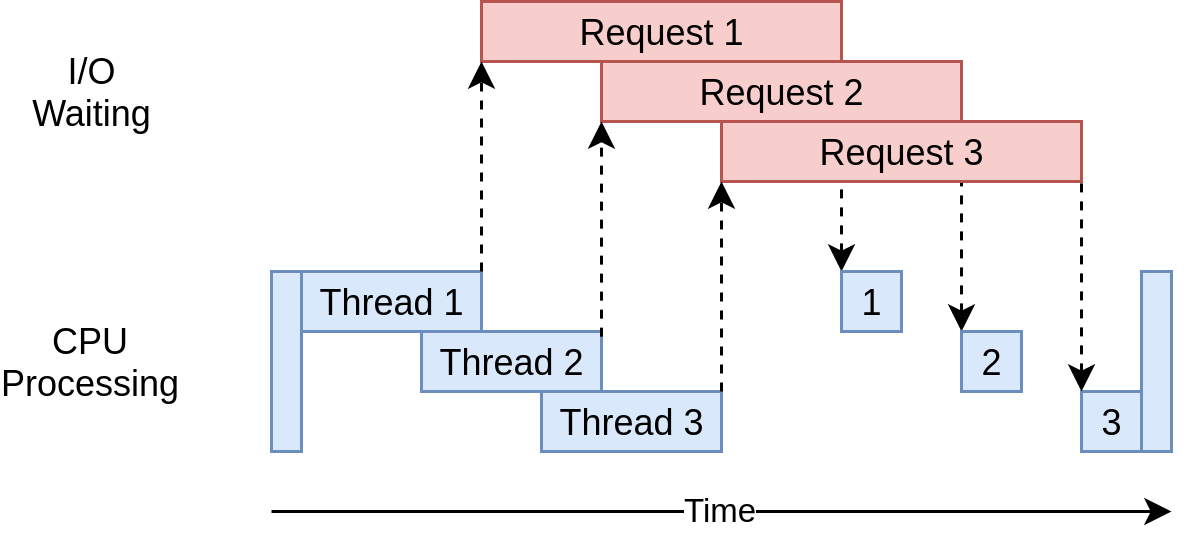
concurrency
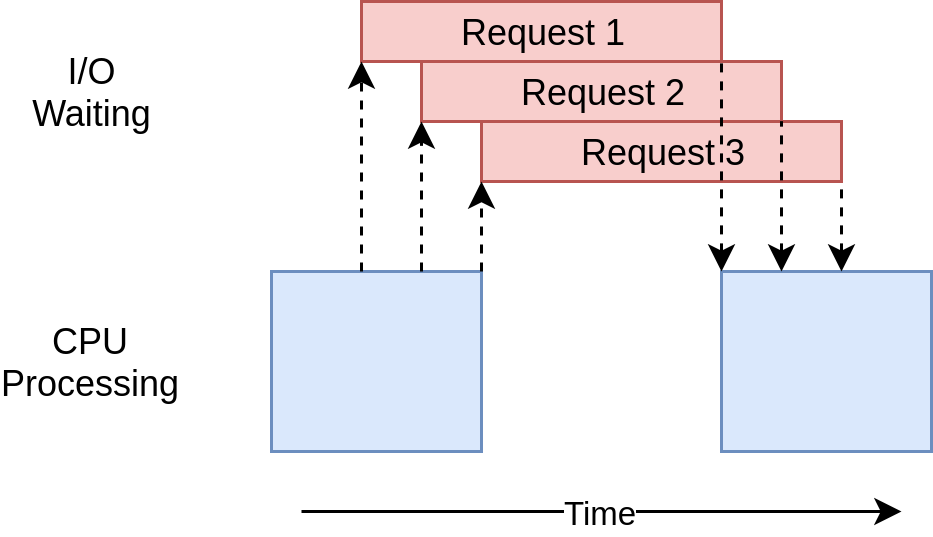 props to real python for the illustrations
both parallelism, and concurrency is a pretty heft topic which i won’t cover much, but if you are interested there are some references1 2 you can skim.
props to real python for the illustrations
both parallelism, and concurrency is a pretty heft topic which i won’t cover much, but if you are interested there are some references1 2 you can skim.
el problemo
Scraping is a great tool to gather (public?) data, thus the process of scraping itself is a kind of slow. In my thesis years, I need to gather a big (4GB) chunk of text from certain news site, which with python it’s kinda slow.
that particular case
let’s start with a kompas shall we? kompas is a well known media company from Indo, thus making it quasi reliable relative to my pov, imo.
Kompas really loves their <p> tags wrapped around a <div class="read__content">.
Then, given a list of kompas links, we should start scraping.
el solusiones
scraping method
the method generally will consist of 5 steps.
- read file into array of string
- get the html
- make the html searchable with a parser
- point the appropriate html tags to scrape
- profit
python
let’s start with python, it’s pretty straightforward because it only need 2 libraries to import: requests to get HTML, bs4 to search the text inside the <p>s (parse the HTML into plain child text).
scrape.py
so given a kompas_link the soup will parse the html into a tree, then the find method fill traversely travel down the stream to search a <p> inside a <div> then make it into an array the concat the array into a string.
Click to show madness
```python def get_paragraf(kompas_link: str) -> str: r = requests.get(kompas_link) reader = soup.find("div",class_="read__content") ```step 1
content = open("./test_links.txt").read().splitlines()
step 2
r = requests.get(kompas_link)
step 3
soup = BeautifulSoup(r.content, "lxml")
step 4
hasil = " ".join([p.text for p in reader.find_all("p") if "Baca juga" not in p.text])
go
go is fucking amusing, i use an amazing scraper library called gocolly/colly it handles requests and parsing altogether (nifty eh), BIG PLUS, it handles concurrency3 too.
scrape.go
step 1
content, _ := ioutil.ReadFile("test_links.txt")
tempLink := strings.Split(string(content), "\n")
var linkArray []string
for _, link := range tempLink {
if link != "" {
linkArray = append(linkArray, link)
}
}
step 2
var pages []string
c := colly.NewCollector(colly.Async())
step 3
c.OnHTML("div[class=read__content]", func(e *colly.HTMLElement) {
pages = append(pages, e.ChildText("p"))
})
step 4
for _, link := range linkArray {
c.Visit(link)
configurations
python 3.7.3
go 1.14.3
results
| Serial | Threading | Multiprocessing | Concurrent | |
|---|---|---|---|---|
| python | 83s | 27.2s | 18.6s | - |
| pycurl | 80s | seg fault | 11.01s | - |
| go | 21s | - | - | 10.5s |
why is python slow?
dissecting its get_paragraph function we can see that

there are two main events here:
- the
requests - the parser
bs4andlxml
requests
 every requests get call needed 0.4s to return. this is the result of
every requests get call needed 0.4s to return. this is the result of requests library that neede to:
requests.get → session.send → urlopen._make_request → validate connection → connect → wrap_socket → return html
parser
 every time we need to find the appropriate
every time we need to find the appropriate <p> tag the bs4 calls so many things, BUT the call speed are logarithmic, which mean the bigger the data the faster it goes constant. amazing.
Constantly growing you say?
let’s see if the method is called 200 times. keep in mind this is run serially.
 as you can see, the more links you provide the slower requests goes, but not bs4 and lxml
as you can see, the more links you provide the slower requests goes, but not bs4 and lxml
python method calling graph

well now as you can see python method call heavily relied on requests, while it takes a long time to do the call. well this is only 200 links, can you imagine if you’re scraping 5*10^4 links? you’ll need a sleeping bag and a good coffee.
so why is go winning?
im not going into the details of the gocolly’s method calls to return a response from kompas’ server, but let us see the graph of all method calls from go’s profiler

to call a function in go, it doesn’t takes too much time, by average it took 0.00002s per function call, compared to python’s 0.00051s. (function calls are the amount of vertices, or duration from traveling from a node to other node)
this is the result of compiled language. Go, being a compiled language doesn’t need to import and make crazy ass tranformation to make the code running. After compiling, the code has already transformed into a bytcode which is a runnable machine readable procedures. whereas python, needed to be “interpreted” everytime it runs.
to put it simply, Golang, firstly build the code into bytecodes, then the machine runs the bytecode. while Python needed time to convert the code into bytecodes to run it, everytime. So which is faster? a tool that has be to be assembled first, or ready to go tools? (tool == program)
conclusion
when it comes to concurrency, hands down there’s no match goroutine’s to the python’s multiprocessing / threading modules.
so don’t be afraid to make your code faster with go’s goroutine if you’re problem is an i/o bound one.
parting words
look i know i make python really bad here, python is actually made from cython. i can code in cython but what differences would it make? a minor one i guess. cython is good for computation, i bet when it comes to a computation problem go and cython (or python + numpy) won’t have a big difference in running time, but on I/O bound cases like this (saving it to disk stuff) concurrency always wins, and the closer you are to code bytecode, the faster and more optimized code you’ll have.
aside from run time, efficiency and all those stupid jargons that i used above, when it comes to the duration to make a script, hands down python is so much easier. it’s up to you to decide whether minimizing the time to code or time to execute.
future improvements
faster-than-requests
entah kenapa selalu error walaupun build dari source, maybe later kalo udah ada waktu, akan di update.
pycurl (without ssl)
beberapa orang saranin kalo emang cuman buat crawling info biasa gak perlu pake SSL (encrypted packets sent through the networks), bisa lebih cepet daripada requests… well, they’re not wrong.
multiprocessing (it’s the fastest there is)
 it’s kinda fast.
it’s kinda fast.
i won’t profile the memory, but im assuming there are no validation on connection handshake between local and kompas’ server and the buffer is a global variable, that’s constantly changing. beda dengan requests yang tiap get harus load ulang dari awal (di instansiasi ulang).
buffer = io.BytesIO()
def get_paragraf(link: str) -> None:
pycurl_get(link, buffer)
soup = BeautifulSoup(buffer.getvalue(), "lxml")
reader = soup.find("div", class_="read__content")
return " ".join(
[p.text for p in reader.find_all("p") if "baca juga" not in p.text.lower()]
)
threading.
seg fault. pasti gara2 buffer io ini tidak thread safe hmm

distributed and parallel
theoretically, if one machine can scrape through the news for 10 seconds, imagine multiple machines. scaling horizontally would be the best option for making scraping news much faster, and wider range of news site.
for python this can be achieved with dask and their workers. set one master as a scheduler then made some slave to be the workers on other computer aside from the master.4
guess for go, i don’t really have many experiences on distributed computing with go, but, go-colly do have some examples on making server within google app engine to make a distributed scraping. although i don’t really know how it works, still you can read on5
with great parallel, comes great honeypot
like uncle ben said, with great power comes great responsibility. having this kind of knowledge, will make a you somekind of a target from the server, imagine you’re hitting them with request continuously for a certain amount of time, and while hitting them, before it even finishes and return the supposed html, you hit em again and again. this makes you an easy target to be banned.
but, no worries with proxies you can be identified as a unique client. pretty undetectable but still prone to honeypot. but no worries, while what you’re scraping is public and doesn’t infringe any copyright you won’t get into any trouble.